The complexity of name matching in modern Taxonomy
For more than two centuries, the Latin naming system has been used to classify organisms, providing a universal way to identify species, a concept commonly referred to as “Taxonomy.” However, the surge in Big Data – massive amounts of information that are difficult to process with traditional tools – has introduced new challenges.
Differences in the classification of species such as inconsistent spelling, duplicate names for the same species (homonyms), and varying taxonomic opinions have made the merging of datasets a big challenge. In fact, 10-20% of species names fail to match perfectly, and often require human intervention or the acceptance of errors, leading to a large time commitment or inaccuracies in datasets.
This phenomenon, which researchers call “data fog,” is becoming a significant barrier to advancing biodiversity research. With big datasets that contain thousands of species, the need for a standardized system to match names is more critical than ever.
About TNLS
To address this challenge, TNLS is developing a unified name matching system capable of accurately matching species names across multiple big datasets. The project will achieve this through the use of stable identifiers, which act as an ID number for a species, even if the name or classification of a species is different across datasets.
Project coordinator, Bart Vanhoorne, explains “The project is developing a unified and transparent approach to name matching Big Data, creating lasting tools that make biodiversity research more accurate, connected, and impactful.”
After the development of the name-matching system, TNLS will focus on:
- Integrating the system into existing datasets, including those on marine and plant species.
- Providing practical support to other institutions integrating the system.
- Creating a notification service to keep researchers up to date on taxonomic changes.
The team behind TNLS
TNLS is led by the Flanders Marine Institute (VLIZ) and supported by the Royal Botanic Garden Edinburgh (RBGE). The project also counts on the expertise of the renowned consultants Walter Berendsohn and Andreas Müller from the Botanischen Garten Berlin.
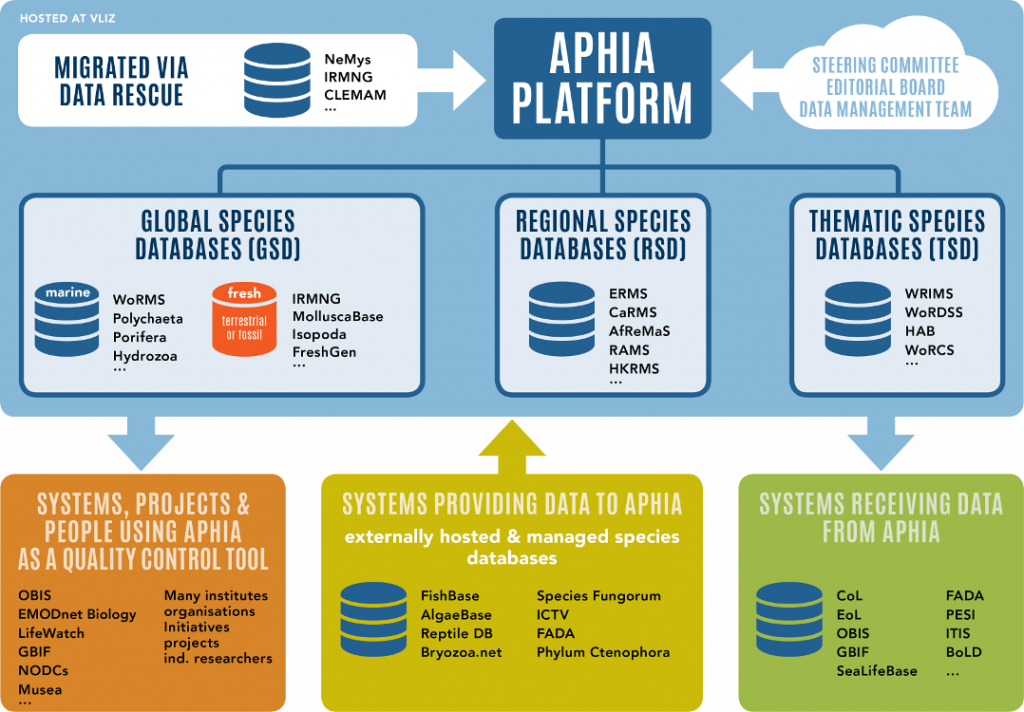
- VLIZ, based in Belgium, serves as both the financial administrator and project manager. Importantly, VLIZ is also the host institute of the World Register of Marine Species, which manages the Aphia database, serving as a backbone for marine biodiversity data.
RBGE, based in Scotland, works in the project as part of their broader contributions to the World Flora Online, particularly through their hosting of the WFO Plant List, serving as a comprehensive database for plant taxonomy.